Reflections from Building my First LLM App
In 2018, I moved to Beijing. As someone who is ethnically Chinese, but grew up in the UK since the age of 5, you can imagine there were a number of adjustments that I needed to go through, from new social customs and the social environnment, to work, to food (although that was an easy one to make!). In the first months, I faced a number of challenges, big and small. One of these small challenges was the ability to infer someone’s gender from their name.
For English names, this seems like a fairly obvious thing for the vast majority of names to do so - we all know that James refers to a man, Sarah to a woman. Although we have fairly neutral names too (e.g. Jo), it’s quite easy to tell for most of them. But, switch the names to Chinese, and suddenly I no longer have that intuition. If you think about it, that makes sense - what makes Sarah a womans name and James a mans name other than a long cultural tradition of it being so? And so, without having that as part of my cultural intuition, it was really impossible for me to tell the gender for Chinese names.
This obviously wasn’t a big problem, and fairly easily resolved (y’know, by just seeing the person face to face). But then, at the start of 2020, just as I joined LinkedIn China, COVID hit and started off a long streak of working from home, and with many colleagues not necessarily in the habit of opening their cameras during meetings, I was left in more of a lurch. Now, knowing or not knowing the gender of the people I was working with obviously didn’t impact how the work was getting done, but as more of the collaboration started to be over text and calls without video, it did leave me on a few occasions accidentally referring to various colleagues via the wrong pronouns, injecting some awkwardness which probably could have been avoided otherwise.
So, this stuck in my mind as a potentially fun ML side project to do. However, I always put it off, mainly because as a supervised learning task putting together the dataset would have been quite a big hassle (I still don’t really know where one would find a clean list of Chinese names mapped to their genders).
Enter the (not so humble) LLM!
In one fell swoop, it seemed to be the key to my little NLP quandary. All I had to do was write the right prompt, and the problem would be solved. To productize this (for I’m sure the millions of other people for whom this is an urgent use case), all I had to do was to formulate the right API call and put it behind a nice frontend. Could it be so simple?
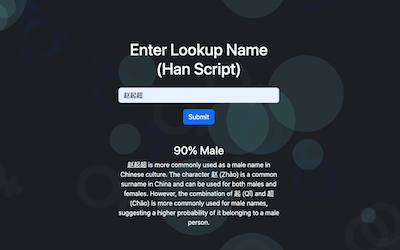
The App (明性)
Well, in a way, yes! Pleased to present to the world: Ming Xing (名性), literally translated as Name Gender. As you may have guessed, I didn’t ask GPT to come up with a name…maybe I should have…
Give it a try!
Architecture
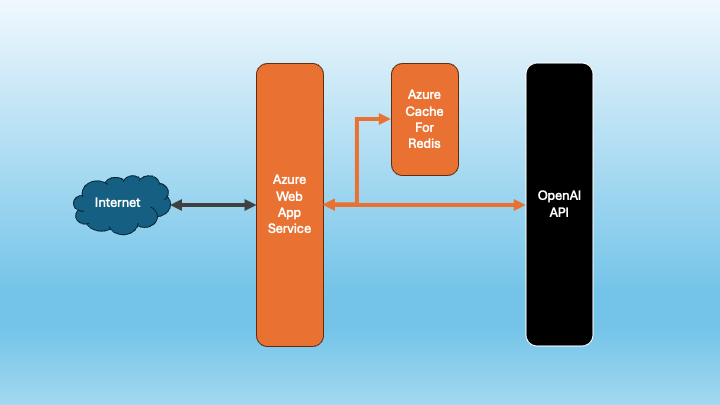
So, obviously we’re not building the next Google here - it’s not that complicated. But one of the areas I wanted to explore as part of this project, aside from incorporating an LLM into a concrete product use case, was setting up this app in a scalable manner using modern cloud tools. So, having used Azure as my cloud provider of choice before I decided to go with it again. After some research, it seemed to me that the right tools for the job were the Azure Web App Service, which could run a Flask app on the frontend. This would be backed with Azure Cache for Redis, which would provide a caching layer to cut down on the number of requests I would have to make to the OpenAI API (cost + performance).
With the framework largely in place. It was relatively quick; taking perhaps 8-10 hours over a few days to get everything ready for public release.
The code can be found here: https://github.com/qichaozhao/mingxing
It was an interesting learning experience, and in that spirit I wanted to share a few musings I had along the way.
Learnings
LLMs are hard to productize
While ChatGPT and Github Co-Pilot have successfully demonstrated some of the incredible strengths of LLM models, I feel that their incorporation into other products and use cases may be more difficult than we first imagine, especially when repeatable and consistent experiences are desired.
The main difficulty comes from the probabilistic output, which we can consider to be non-deterministic. When the LLMs outputs are to be consumed by code as part of a program rather than directly being consumed by humans, that is where the difficulties lie.
Case in-point, in order to make 名性 work, I relied upon the OpenAI API to return a JSON formatted as follows:
{
"male": float,
"female": float,
"reasoning": string
}
However, even though I expressly included in the prompt to return only the JSON format, I have no guarantees that that is what I will get back. It seems to work the majority of the time, but when it doesn’t work there is no way to debug why.
The prompt:
You are a language processor which evaluates the probability of a Chinese name belonging to a
male or female person and provide reasoning. Return only JSON in the following form: {"male": <X>, "female": <Y>, "reasoning": <YOUR_REASONING>}.
I think this kind of non-deterministic behaviour will ultimately mean that LLMs definitely cannot be directly incorporated for many mission-critical applications where such guarantees need to be in place, and even for non mission-critical or frivolous use cases it will generate poor user experiences when a user request cannot be serviced because the LLM won’t co-operate.
It’s possible to put safeguards (for 名性 I just added in some exception handling to allow graceful failure, but I can imagine other solutions such as re-prompting until the right output format is returned), but overall you need to code very defensively when working with an LLM as opposed to a “normal” API (but this may force better developer practices anyway, so maybe it’s a good thing? Ha!)
Comparison with an existing tool
After I was building this tool and thinking about buying a domain for it (y’know, just in case it could become a useful niche product), I happened across an existing service that also offers a lot of name analysis tools (Namsor). As far as I can tell, it was founded in 2015 so it would have had to use “traditional” methods for the most part.
Based on a quick spot check test between 名性 and Namsor of a few of my own and my friends names, I found the gender identification function returns probabilities that are within 10% of each other. Although the sample size is too small to draw firm conclusions and there is no definitive “test set” I can use to validate the accuracies, the fact that this LLM based approach is fairly close (at least on these few samples) to what seems like a fairly mature service and tool is pretty amazing to say the least.
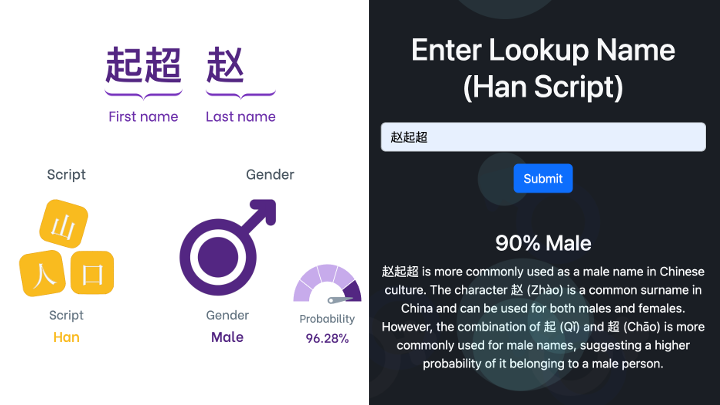
Namsor (left) vs Ming Xing (right) for my own name
I can only imagine the effort the Namsor team would have gone to over the years with various supervised ML approaches, incorporating domain knowledge from linguists, taxonomists and various other language researchers across the globe to build these tools. Not to mention the effort it would have taken to build up clean datasets for use for training.
What does this mean though?
Well, assuming the quality of the results stays roughly consistent with the tested samples so far (this is a big if), it means an LLM based approach may be able to be much cheaper. Namsor’s MEGA tier is $999 per month for 1 million requests (~$0.000999 per request), and has an overage charge of $0.001 USD per request. So I think we can take this figure as a comparison basis.
OpenAI’s GPT3.5-Turbo API costs ~$0.00035 per request (based on the input being ~60 tokens and output ~130 tokens, which is a rough average of my requests thus far). This means on a per request basis, this approach is maybe 2-3x cheaper (*many disclaimers with this rough calculation apply obviously, and this is in no way a dig at Namsor’s current pricing model)!
But, it does beg the question. If we could switch these kinds of applications to run on LLMs, would there be an opportunity for many NLP based products to get cheaper in the future (assuming quality holds)? That could only be good for everyone.
Basic DevOps is now totally commodified
I started dabbling in tech before container tools like Docker were widely adopted (this makes me officially old I guess?). For a lot of my tech career deploying and maintaining apps involved hacking around on a command line, understanding some amount of Linux, and if you wanted to automate things, a fair amount of custom written glue code usually in Bash or something similar.
Now though, I feel technology really has moved on, and these DevOps skills have become somewhat obsolete for a large portion of the developer community. This is a good thing for productivity overall, it means that developers can focus on business logic and spend less time working out how to go from development to production, but, as someone who does enjoy hacking around linux boxes and keeping stuff running, I do lament the loss of the need and opportunities to deploy this skillset going forwards.
I was most impressed by how easy it was to set everything up; no need to touch a CLI, everything done through a fairly well presented UI. Although I think getting to an initial deployed and working app was still slower than me just requisitioning an instance and doing it manually, everything afterwards (e.g. CI/CD linked with Github actions, scaling, the ability to add extras like DDoS protection) truly trumps anything home-rolled.
For a large portion of SME use cases, would there really need to be anything more?
The only pain point I encountered was how to manage secrets. In this case, the app relied on a config.py & .env file (which is not pushed to git) which holds instance specific secrets. These would be pushed to the instances directly at deploy time to be consumed by the app.
In Azure at least, there didn’t seem to be an easy way of making this happen easily. I understand there is the possibly to customise the deployment script to make something like this happen, but I think it would have been easier to enable a feature to host secret config files and inject them into the desired directories automatically.
In the end, I configured every secret as a environment variable through the Azure portal which was then subsequently injected into the instance, but it required some slight tweaking on how the app read config variables to make it work.
Conclusions
So, that’s about it for this blog post, hope you enjoyed reading it! Please feel free to share any comments or feedback you may have!
Till next time!
-qz